




관련상품

텐서플로우 설치

BERT 구글 AI
AI 게시판, 자동 글쓰기 AI 서비스

인공지능 AI 쇼핑몰 – 쇼팅

인공지능 AI 챗봇 – 리트센

아마존 리눅스 ( Linux ) 설치

이미지 데이터셋 알고리즘
홈페이지 제작 / 웹사이트 제작

SEO 구글 검색엔진최적화 강의
블로그 쇼핑몰 인공지능 AI 이미지
상품 정보
상품 기본설명
구글 리눅스 서버 기술 지원 서비스는 현대적인 웹 개발 환경과 AI 연동 서비스의 수요에 발맞추어 고안되었습니다. 이 서비스는 OpenAI의 ChatGPT API, Google Translate API와 같은 다양한 AI 기술 통합을 지원하는 데 필수적인 서버 기술들에 대한 전문 지원을 제공합니다. Apache와 Node.js를 통한 서버 사이드 스크립팅, MySQL과 MariaDB를 사용한 데이터베이스 관리, 그리고 PHP와 Nginx를 활용한 웹 서버 구축 및 운영에 이르기까지, 이 서비스는 개발자가 최신 웹 기술과 AI 연동 기능을 손쉽게 통합할 수 있는 강력한 기반을 마련해 줍니다.
상품 상세설명
구글의 리눅스 서버 기술 지원은 복잡한 서버 환경 구축 및 관리의 부담을 줄여주며, 고객이 AI와 같은 첨단 기술을 자신의 서비스에 효율적으로 도입하고 활용할 수 있도록 돕습니다. 최적화된 서버 성능과 보안, 그리고 신속한 문제 해결을 통해 개발자는 기술적 도전과제에 더 집중할 수 있으며, 기업은 안정적인 서비스 운영을 통해 시장에서의 경쟁력을 강화할 수 있습니다. 구글 리눅스 서버 기술 지원을 통해, AI 연동 서비스의 개발과 운영이 한층 더 간소화되고 효율적으로 변화됩니다.
구글 리눅스 서버 기술 지원 서비스 상세 설명
구글 리눅스 서버 기술 지원 서비스는 최신 웹 개발 트렌드와 AI 통합의 요구사항에 부응하는 전문 기술 지원을 제공합니다. 이 서비스는 구글의 강력한 클라우드 인프라와 리눅스(CentOS 9) 환경에서 Apache, MariaDB(MySQL), PHP 등의 주요 웹 기술 설치와 구성을 포괄하는 광범위한 지원을 제공합니다. 다음은 구글 리눅스(CentOS 9) 서버에서 이러한 기술을 설치하고 구성할 때 제공되는 상세 지원 내용입니다.
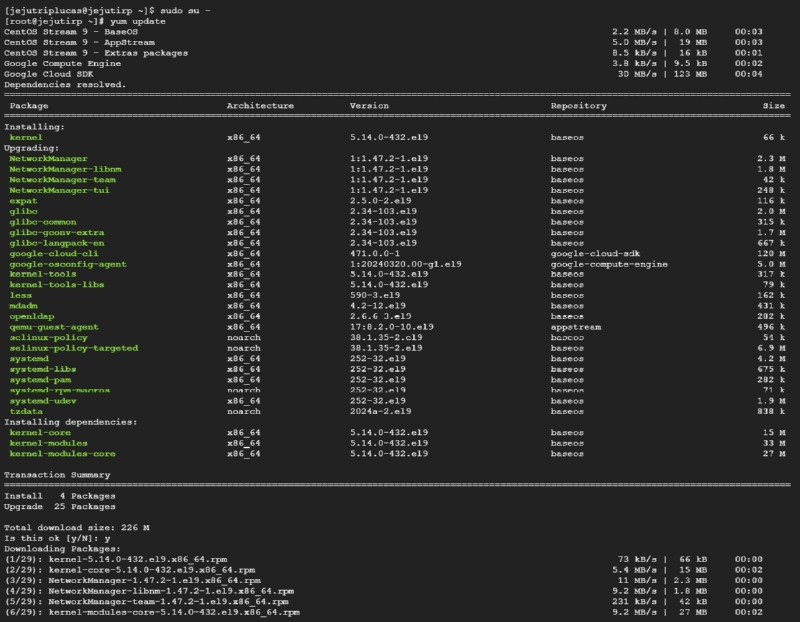
1. Apache 설치 및 구성 지원
설치 지원: Apache 웹 서버의 최신 안정 버전 설치를 위한 지침 제공.
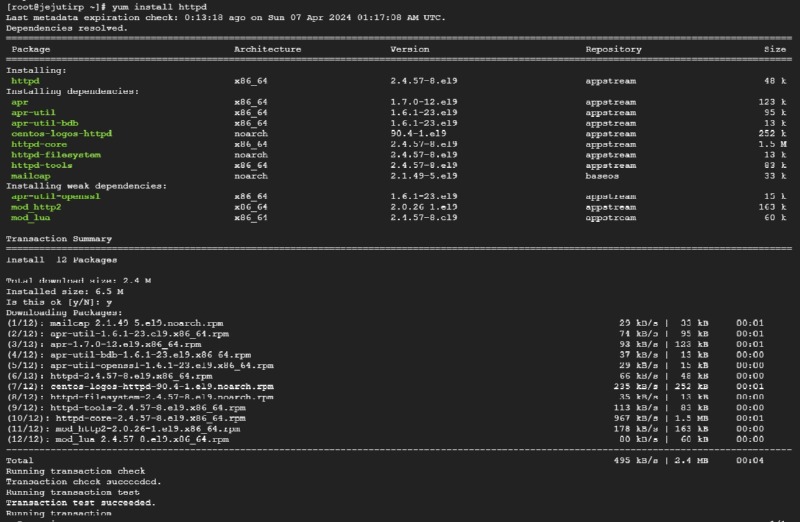
구성 최적화: 고성능과 보안을 위한 Apache 서버 구성 최적화 방법 제공.
모듈 통합: 필요한 Apache 모듈의 설치 및 구성 지원, 예를 들어 보안(SSL) 모듈, URL 재작성 모듈 등.
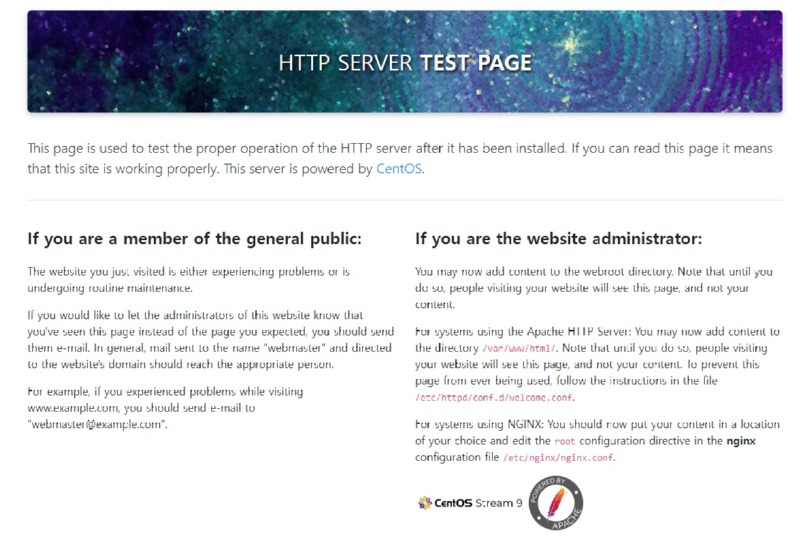
문제 해결: Apache 서버 운영 중 발생하는 문제에 대한 진단 및 해결 방안 제공.
2. MariaDB(MySQL) 데이터베이스 설치 및 최적화 지원
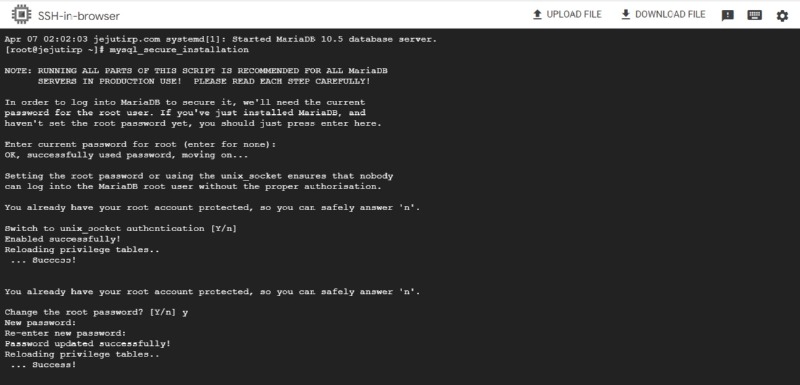
데이터베이스 설치: MariaDB 또는 MySQL의 설치 및 초기 설정 지원.
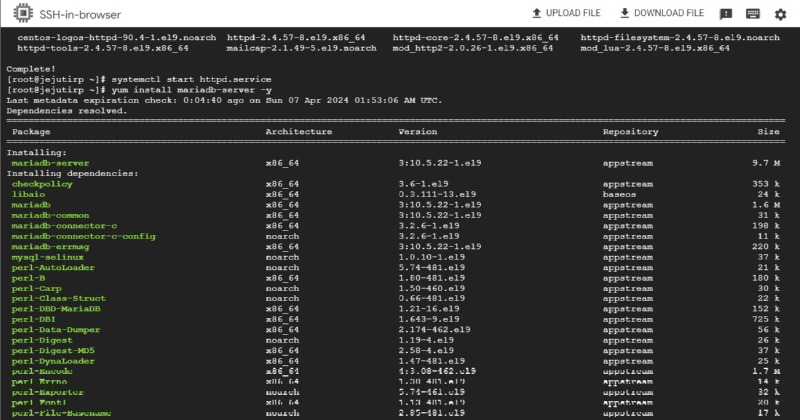
데이터베이스 데몬 Start 상태 확인
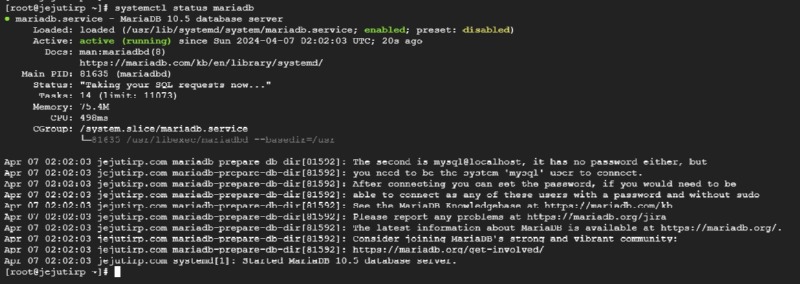
보안 설정: 데이터베이스 접근 보안 강화를 위한 권장 사항 제공.
성능 최적화: 데이터베이스 성능을 극대화하기 위한 구성 및 튜닝 지원.
백업 및 복구: 데이터 손실 방지를 위한 백업 전략과 복구 프로세스 지원.
3. PHP 설치 및 구성 지원
PHP 설치: 웹 애플리케이션 개발에 필요한 PHP 버전 설치 지원.
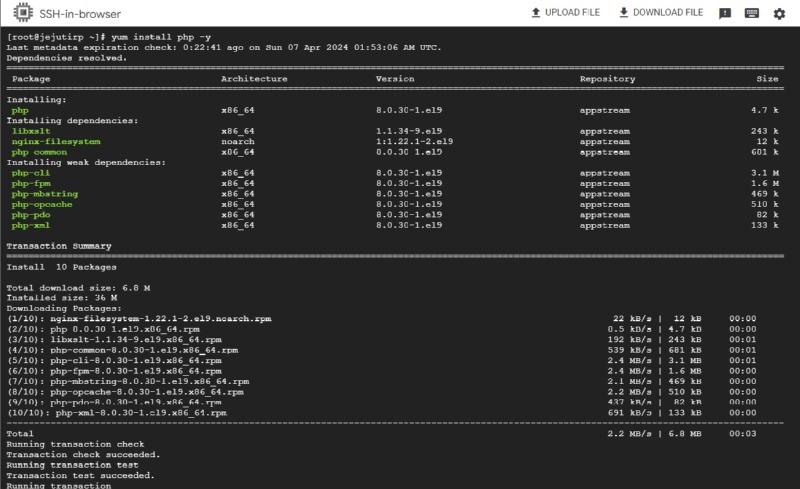
서버 통합: PHP와 Apache, Nginx 웹 서버 간의 효율적인 통합 방법 제공.
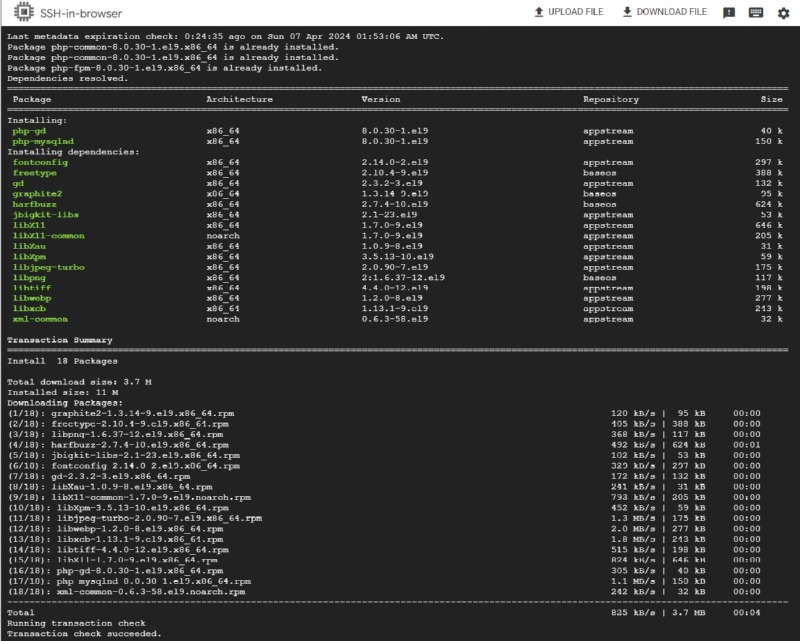
성능 향상: PHP 성능 향상을 위한 OPcache 등의 캐싱 메커니즘 설정 지원.
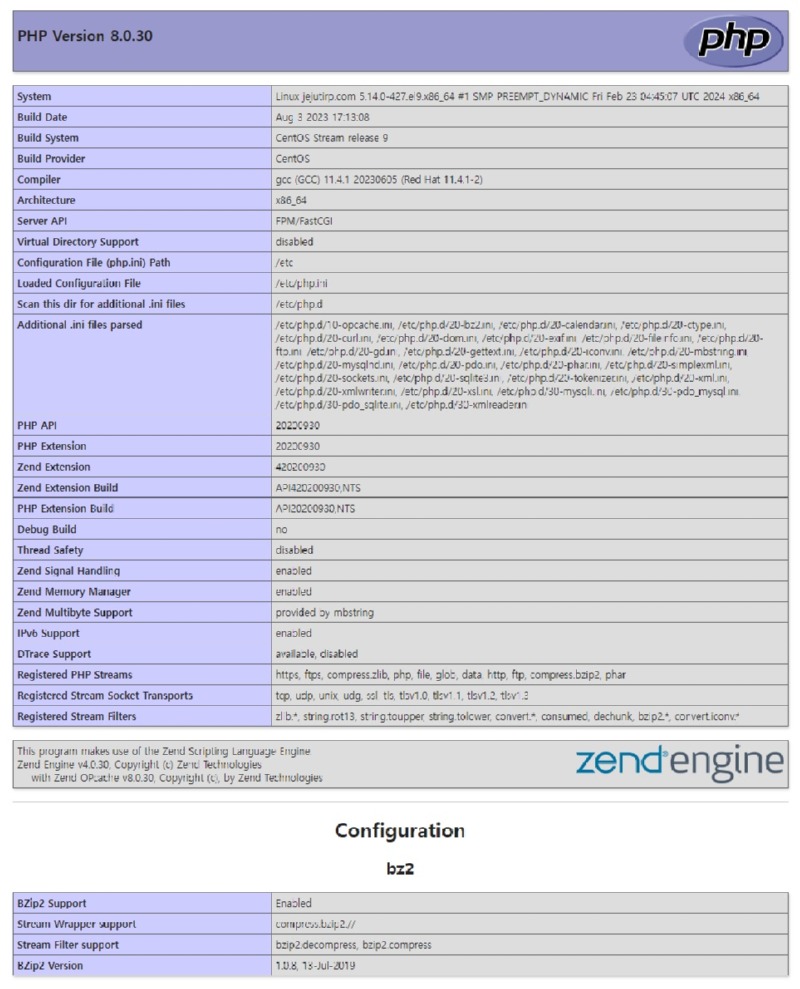
보안 조치: PHP 설정을 통한 웹 애플리케이션 보안 강화 방법 제공.
4. 기술 지원 및 문서
상세 문서 제공: 각 기술 구성 요소에 대한 상세 설치 및 구성 문서 제공.
24/7 기술 지원: 전문 기술 지원팀이 제공하는 연중무휴 문의 응답 서비스.
커뮤니티 액세스: 개발자 커뮤니티와의 상호작용을 통해 지식 공유 및 추가 지원.
구글 리눅스 서버 기술 지원 서비스는 이러한 상세 지원을 통해 개발자와 기업이 리눅스 기반 서버 환경에서의 웹 애플리케이션 개발 및 운영을 원활하게 진행할 수 있도록 지원합니다. 이 서비스는 최신 웹 기술과 AI 통합 프로젝트의 성공적인 구현을 위한 강력한 기반을 제공합니다.
5. AI 에 관련된 사항은 각 서비스 별로 혹은 설치가 필요한 형태의 OS 등 별로 별도 지원합니다.

자주 묻는 질문
서버에 접속이 되지 않아요
- 방화벽 규칙이 올바르게 설정되었는지 다시 확인합니다. 콘솔에서 VPC 네트워크 > 방화벽으로 이동하여 SSH 포트(22)를 모든 IP에서 허용하도록 설정합니다.
- ping 조차 되지 않는 경우가 있습니다.
메타데이터에서 serial-port-enable (key) , true ( value ) 설정 후 직력1포트로 직접 접속을 시도합니다.
Classification and Prediction Model for Good/NG (Supervised Learning)
Classification and Prediction Model for Good/NG (Supervised Learning)와 같은 프로그램을 제공하는 서비스는 여러 가지가 있습니다.
이러한 서비스는 머신러닝 모델을 쉽게 개발, 학습, 배포할 수 있도록 도와줍니다.
주요 클라우드 서비스 제공업체와 오픈소스 플랫폼, AutoML 서비스 등을 통해 이러한 유형의 프로그램을 구축할 수 있습니다.
주요 서비스 제공업체 및 플랫폼
#### 1. Amazon Web Services (AWS)
- Amazon SageMaker:
- 완전 관리형 서비스로, 머신러닝 모델을 쉽게 구축, 학습, 배포할 수 있도록 지원합니다.
- 다양한 알고리즘과 프레임워크(TensorFlow, PyTorch 등)를 지원합니다.
- 자동화된 모델 튜닝 및 배포 기능을 제공합니다.
- [AWS SageMaker](https://aws.amazon.com/sagemaker/)
#### 2. Google Cloud Platform (GCP)
- Google AI Platform (Vertex AI):
- 머신러닝 모델을 쉽게 구축, 학습, 배포할 수 있는 플랫폼을 제공합니다.
- AutoML을 통해 코드 작성 없이 모델을 자동으로 학습시킬 수 있습니다.
- TensorFlow Extended(TFX)를 통해 엔드 투 엔드 ML 파이프라인을 지원합니다.
- [Google AI Platform (Vertex AI)](https://cloud.google.com/vertex-ai)
#### 3. Microsoft Azure
- Azure Machine Learning:
- 머신러닝 모델을 개발, 학습, 배포할 수 있는 완전 관리형 클라우드 서비스입니다.
- Jupyter Notebook과 통합되어 사용하기 편리합니다.
- AutoML을 통해 모델을 자동으로 생성할 수 있습니다.
- [Azure Machine Learning](https://azure.microsoft.com/en-us/services/machine-learning/)
#### 4. IBM Cloud
- IBM Watson Machine Learning:
- 머신러닝 모델을 개발, 학습, 배포할 수 있는 클라우드 서비스입니다.
- AutoAI를 통해 데이터 준비, 모델 개발, 하이퍼파라미터 튜닝, 배포를 자동화합니다.
- [IBM Watson Machine Learning](https://www.ibm.com/cloud/machine-learning)
#### 5. H2O.ai
- H2O.ai:
- 오픈소스 머신러닝 플랫폼으로, 다양한 알고리즘과 자동화된 머신러닝(AutoML)을 지원합니다.
- H2O Driverless AI를 통해 모델 개발을 자동화할 수 있습니다.
- [H2O.ai](https://www.h2o.ai/)
#### 6. DataRobot
- DataRobot:
- 자동화된 머신러닝 플랫폼으로, 모델 개발, 학습, 배포를 자동화합니다.
- 엔터프라이즈 수준의 모델 배포 및 관리 기능을 제공합니다.
- [DataRobot](https://www.datarobot.com/)
### 예시: AWS SageMaker를 사용한 Classification and Prediction Model
아래는 AWS SageMaker를 사용하여 Good/NG 분류 모델을 학습하고 배포하는 예시 코드입니다.
1. 환경 설정 및 데이터 준비:
```python
import boto3
import sagemaker
from sagemaker import get_execution_role
# SageMaker 세션 및 역할 설정
sagemaker_session = sagemaker.Session()
role = get_execution_role()
# S3 버킷 설정
bucket = 'your-s3-bucket'
prefix = 'good-ng-data'
data_path = 's3://{}/{}'.format(bucket, prefix)
# 데이터 업로드
sagemaker_session.upload_data(path='data/train.csv', bucket=bucket, key_prefix=prefix + '/train')
sagemaker_session.upload_data(path='data/validation.csv', bucket=bucket, key_prefix=prefix + '/validation')
```
2. 모델 학습:
```python
from sagemaker.estimator import Estimator
# Estimator 설정
container = sagemaker.image_uris.retrieve('linear-learner', boto3.Session().region_name)
linear = Estimator(container,
role,
instance_count=1,
instance_type='ml.m4.xlarge',
output_path='s3://{}/{}/output'.format(bucket, prefix),
sagemaker_session=sagemaker_session)
# 하이퍼파라미터 설정
linear.set_hyperparameters(feature_dim=30, # 피처 수
predictor_type='binary_classifier',
mini_batch_size=100)
# 학습 데이터 설정
train_data = sagemaker.inputs.TrainingInput(s3_data=data_path + '/train', content_type='csv')
validation_data = sagemaker.inputs.TrainingInput(s3_data=data_path + '/validation', content_type='csv')
# 모델 학습
linear.fit({'train': train_data, 'validation': validation_data})
```
3. 모델 배포 및 예측:
```python
# 모델 배포
linear_predictor = linear.deploy(initial_instance_count=1, instance_type='ml.m4.xlarge')
# 예측 수행
import json
from sagemaker.predictor import csv_serializer, json_deserializer
linear_predictor.serializer = csv_serializer
linear_predictor.deserializer = json_deserializer
# 예측 데이터
data = '1.2,3.4,5.6,...\n' # 피처 데이터
result = linear_predictor.predict(data)
print('Prediction:', result)
```
요약
- 여러 클라우드 서비스와 오픈소스 플랫폼에서 Good/NG 분류 모델을 개발, 학습, 배포할 수 있습니다.
- AWS SageMaker, Google AI Platform, Azure Machine Learning, IBM Watson Machine Learning, H2O.ai, DataRobot 등이 주요 서비스입니다.
- 이러한 서비스를 사용하면 데이터 준비, 모델 학습, 하이퍼파라미터 튜닝, 배포 등을 자동화하여 쉽게 사용할 수 있습니다.
- 예시로 AWS SageMaker를 사용하여 Good/NG 분류 모델을 구축하고 배포하는 과정을 보여드렸습니다.
데이터베이스 사용의 예
속도는 데이터베이스 선택에서 중요한 고려 사항입니다. 속도는 여러 요인에 의해 영향을 받을 수 있으며, 특정 사용 사례에 따라 다를 수 있습니다. MongoDB와 PostgreSQL(JSONB 사용)을 비교할 때, 각각의 장단점을 살펴보면 다음과 같습니다:
### MongoDB의 속도 장점
1. 쓰기 속도:
- MongoDB는 NoSQL 데이터베이스로, 스키마가 유연하고 데이터 쓰기가 빠릅니다. 데이터를 문서 형태로 저장하며, 인덱스가 없는 경우 쓰기 속도가 매우 빠릅니다.
2. 수평적 확장성:
- MongoDB는 샤딩을 통해 수평적으로 확장할 수 있어 대용량 데이터에 대해 높은 쓰기 및 읽기 성능을 제공합니다.
3. 읽기 속도:
- 인덱스를 잘 설계하면 읽기 속도도 매우 빠릅니다. 특히, 복제본에서 읽기 작업을 분산하여 성능을 최적화할 수 있습니다.
4. 캐싱:
- 메모리 내에서 데이터를 캐싱하여 자주 접근하는 데이터에 대해 빠른 읽기 속도를 제공합니다.
### PostgreSQL(JSONB 사용)의 속도 장점
1. 관계형 데이터 처리:
- 복잡한 관계형 데이터 처리를 빠르게 수행할 수 있으며, 조인과 트랜잭션 성능이 우수합니다.
2. 인덱싱:
- JSONB 필드에 대한 GIN 인덱스를 사용하여 복잡한 쿼리에 대해 높은 성능을 제공합니다.
3. 트랜잭션 처리:
- ACID 트랜잭션을 지원하여 데이터 일관성을 유지하면서 빠른 성능을 제공합니다.
### 속도 비교
- 쓰기 작업: MongoDB가 더 유리합니다. MongoDB는 스키마가 유연하고, 데이터 삽입 작업이 매우 빠릅니다.
- 읽기 작업: 단순한 읽기 작업은 MongoDB가 유리하지만, 복잡한 쿼리와 관계형 데이터 처리는 PostgreSQL이 더 빠를 수 있습니다.
- 인덱스 사용: 인덱스를 잘 설계하면 두 데이터베이스 모두 빠른 읽기 성능을 제공하지만, MongoDB는 대규모 데이터를 인덱싱할 때 더 유연합니다.
- 확장성: MongoDB는 수평적 확장성이 뛰어나 대규모 데이터에 대해 더 나은 성능을 제공합니다.
### 실제 예시
#### MongoDB
```python
from pymongo import MongoClient
import time
# MongoDB 연결 설정
client = MongoClient('mongodb://localhost:27017/')
db = client['speed_test']
collection = db['test_data']
# 데이터 삽입 속도 테스트
start_time = time.time()
data = [{"field": i} for i in range(1000000)]
collection.insert_many(data)
print(f"MongoDB Insert Time: {time.time() - start_time} seconds")
# 데이터 읽기 속도 테스트
start_time = time.time()
results = list(collection.find({"field": {"$gte": 999000}}))
print(f"MongoDB Read Time: {time.time() - start_time} seconds")
```
#### PostgreSQL
```python
import psycopg2
import time
# PostgreSQL 연결 설정
conn = psycopg2.connect("dbname=speed_test user=youruser password=yourpassword")
cur = conn.cursor()
# 테이블 생성
cur.execute("CREATE TABLE IF NOT EXISTS test_data (id SERIAL PRIMARY KEY, field INT)")
conn.commit()
# 데이터 삽입 속도 테스트
start_time = time.time()
data = [(i,) for i in range(1000000)]
cur.executemany("INSERT INTO test_data (field) VALUES (%s)", data)
conn.commit()
print(f"PostgreSQL Insert Time: {time.time() - start_time} seconds")
# 데이터 읽기 속도 테스트
start_time = time.time()
cur.execute("SELECT * FROM test_data WHERE field >= 999000")
results = cur.fetchall()
print(f"PostgreSQL Read Time: {time.time() - start_time} seconds")
# 연결 종료
cur.close()
conn.close()
```
### 요약
- MongoDB는 대규모 데이터 삽입과 간단한 읽기 작업에 대해 더 빠른 성능을 제공할 수 있습니다.
- PostgreSQL은 복잡한 쿼리와 관계형 데이터 처리에 대해 더 빠른 성능을 제공할 수 있습니다.
- 확장성 측면에서 MongoDB가 더 유리하며, 대규모 데이터 처리에 적합합니다.
- 데이터 일관성이 중요한 경우 PostgreSQL이 더 나은 선택일 수 있습니다.
결국, 사용 사례와 데이터의 특성에 따라 적합한 데이터베이스를 선택하는 것이 중요합니다.
MongoDB는 유연성과 확장성이 요구되는 대규모 데이터 처리에 적합하고,
PostgreSQL은 데이터 일관성과 복잡한 쿼리 성능이 중요한 경우에 적합합니다.
